Gospel of LSTMs; How I wrote 5th Gospel of Bible using LSTMs
- 8 minsI was sunkissed by Recurrent Neural Networks (RNNs) once I had joined Perleybrook Labs in mid of 2017. We were working on an ambitious sequence to sequence modeling task at that point in time. I must say, the knowledge curve was steep. MOOCs, blogs, tutorials… you name it, I’ve done it to keep up the pace. I bumped into a lot of GitHub repos, learned multiple deep learning frameworks, coded, failed, coded again, failed again and finally here I’m writing this post on a recent side project of mine using RNNs …
Life is good, ain’t it?

Okay, for last three months, I’ve been banging my head on a language modeling task. I’ve written two decent tutorials on Language Modelling and RNNs in general, which are the subsidiaries of the trauma and anxiety I endured during this time period. If you’re not allergic to partial differential equations, optimization techniques, and Python, then Merry Christmas at here and here. Have a look and bounce back.
Others may stay here with me here since I’m not going to write anything geeky in this post.
Well, I’m 😕
No, you’re not 😐
No, I’m 😕
Okay, a little bit 😒
YASSS !!! I like it when people are morally flexible 🤩
Language Modelling
Language modeling was tough for us when we were at the age of three, maybe? Because generating words or characters by maintaining the context is the deal. Yes, this is still hard when it comes to job interviews, academical vivas, feminism, immigration, child molestation in Catholic Church and LGBT rights. But you got the point anyway.
But for computers, it was uphill. Maintaining the context was tough until RNNs happened to us. Better go to my tutorial links, before you dare to ask how RNNs do it.
Now the task is simple. Train the RNNs on the desired data, learn the context, generate new content with the learned context. Holy Moly !!!
Data
Here is the thing. I chose Gospels of Bible to train my Long Short-Term Memory (variant of RNNs) cells to generate a new machine-generated Gospel. I call it the “Gospel of LSTMs”. Why I chose the Gospel data? Read until the end.
Now, let me enlist the challenges I’ve faced during the journey.
Challenge One — Aleyamma Joseph
Correct. That’s my mother (Translates to Elizabeth Joseph for non-Keralites). Being a true believer, she won’t allow me touching the holy scriptures for a “hobby project”.
Solution: I didn’t tell her. (Since she doesn’t have an active social media presence, it is less likely that she is going to know about this whole conundrum in future either.)
Challenge two — Data size
Since LSTMs has to learn everything from the scratch, just getting texts of four gospels didn’t help.
Solution: Thanks to almost 162 different translations of Bible to English, I could select the following seven versions to gather a decent data size.
- American Standard (ASV) — 1901
- Bible in Basic English (BBE) — 1949
- Darby English Bible (DARBY) — 1890
- King James Version (KJV) — 1611
- Webster’s Bible (WBT) — 1833
- World English Bible (WEB) — 2000
- Young’s Literal Translation (YLT) — 1862
Selection criteria: Easy availability. Thanks.
Challenge three — Cleaning the raw data
Though the data was quite neatly arranged, I had to remove the World English Bible (WEB) version since the data was too messy to clean. You can find the data preparation Jupyter notebooks in the project repo.
Challenge four — Structured generation
Bible is composed in chapters and verses. How to generate them in that format?
Solution: Train the network to learn the format. Simple. In favor, I’ve added four more tokens to vocabulary.
- **
** — Start of the chapter - **
** — End of the chapter - **
*** *— Start of the verse - **
** — End of the verse
Challenge five — Finding the best model
It is really tough to land up in the perfect model which can reduce the validation and training loss adequately. So I chose a wise and well-adopted strategy on this.
Strategy: Train as many models as you could day and night, putting your sleep on the line. Chose the best model from them.
Challenge six — Issues with St. Mark
Using Gospel of Mark as a validation was hard for my LSTMs to figure out how to optimize the loss. First I thought it was the wrath of God. Then I approached the problem pragmatically and found the following reasons.
- Gospel of Mark is the shortest among the gospels. It has only 16 chapters.
- Starting and ending of the Gospel of Mark is completely different from other gospels. He doesn’t start the gospel with genealogy. He ends the gospel with no mention of the post-resurrection appearance of Christ to women on Easter morning.
- Mark treated Jesus as a “Marvel” superhero and kept the focus on his heroic deeds as an exorcist, a healer, and a miracle worker. He added the activities of healing deaf and dumb, the blind man at Bethsaida which are unaccounted in other gospels. Same time, he chucked the virgin birth of Jesus and there is no mention of Joseph, husband of Holy Mary.
- Bizarre writing patterns. Eg. the use of the word
immediatelyis not less than 40 in the entire Gospel and 12 times in a chapter.
Now the whole point is, Mark was different. See the validation and training loss plot against epochs with the same hyperparameters.
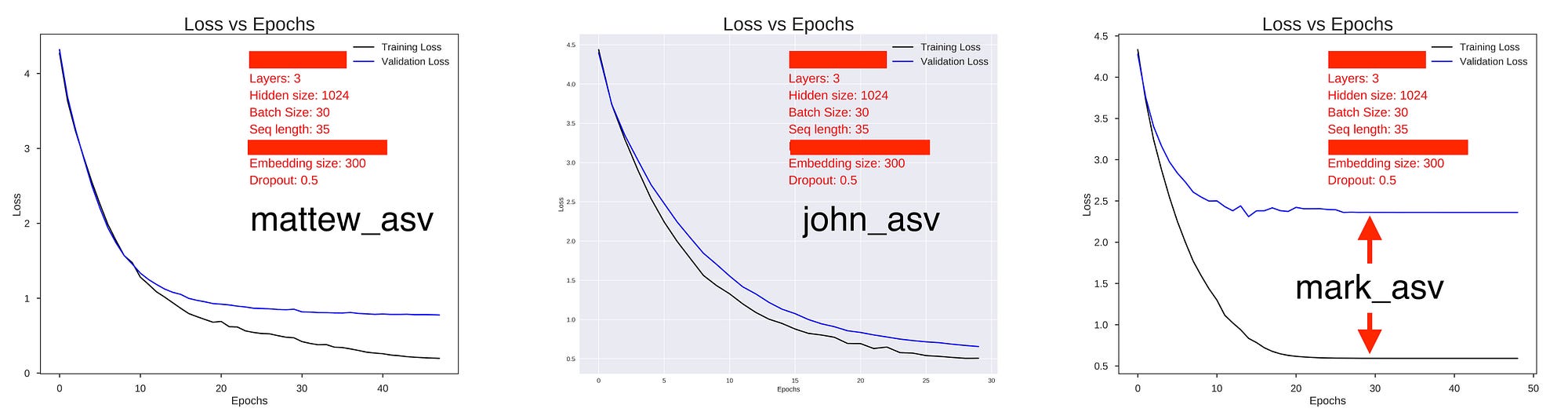
Don’t confuse the above characteristics with overfitting. The model is not overfitting, rather gets a hard time to fit Mark because of aforementioned vulnerabilities. So, I particularly avoided Mark being used as validation data. The best model in the project repo is validated on Matthew (American Standard Version).
Challenge seven — Sampling
To resemble a Gospel, there should be some baseline of metrics. How many chapters, how many verses in each chapter, etc.
Solution: Exploratory data analysis (EDA). From EDA, I figured out that, there is an average of 20–30 chapters which will be approximately 25000 words. There is an average of 20–60 verses in each chapter. So, the maximum limit of the number of verses in a chapter is set to 60. You may find the bible stats JSON file and EDA Jupyter notebook in the project repo.
Observations
Seems like, the trained model could learn and mimic the writing pattern of Gospels really well. Have a look at these samples.
Sample One — Original Matthew_ASV Chapter 4, Verses 18–22
18 And walking by the sea of Galilee, he saw two brethren, Simon who is called Peter, and Andrew his brother, casting a net into the sea; for they were fishers.
19 And he saith unto them, Come ye after me, and I will make you fishers of men.
20 And they straightway left the nets, and followed him.
21 And going on from thence he saw two other brethren, James the son of Zebedee, and John his brother, in the boat with Zebedee their father, mending their nets; and he called them.
22 And they straightway left the boat and their father, and followed him.
Sample One — Generated Matthew_ASV Chapter 3, Verses 5–9
5 Now as he walked by the sea of Galilee , he saw Simon and Andrew his brother casting a net into the sea : for they were fishers .
6 And Jesus said unto them , Come ye after me , and I will make you to become fishers of men .
7 And straightway they forsook the nets , and followed him .
8 And going on from thence he saw two other brethren , James the ‘ son ‘ of Zebedee , and John his brother , in the ship with Zebedee their father , mending their nets ; and he called them .
9 And they straightway left the ship and their father , and followed him .
Can you pick up the nuances added by model? The generated version is not the copy of original text. Rather, model is narrating the incident in its own words. Cool, ain’t it?
But the model is not perfect. It made many factual errors as well. See the following.
Sample two — Generated Matthew_ASV Chapter 7, Verses 3–6
3 and he besought him much , saying , My little daughter is at extremity ; [ I pray ] that thou shouldest come and lay thy hands upon her so that she may be healed , and may live .
4 And he went with him , and a large crowd followed him , and he healed him , and said ,
5 Lord , if thou wilt , thou art able to cleanse me .
6 And he stretched forth his hand , and touched him , saying , I will ; be thou made clean . And straightway the leprosy departed from him .
This is an incident described only by Mark at Chapter 5, Verses 23–43. Two points need to noted here.
- An incident described only in Gospel of Mark is added to Gospel of Matthew. At one glance, the narration seems to be so coherent, only a well-acquainted Bible expert can spot this addition immediately. This is a harmless example, but what about the injections that are based on promoting a propaganda? Bible versions are prone to these additions and deletions.
- Though the narration started with tale of daughter of Jairus, the ruler of the synagogue, it ended up at cure of Jarius from leprosy, which is completely disconnected from context. This is a notable misinterpretation by the model.
Sample three — Generated Luke_ASV Chapter 3, Verses 1–6
1 And Jesus, the son of Abraham, the ‘son‘ of Abraham, the ‘son‘ of Abraham, the ‘son‘ of Terah, the ‘son‘ of Naho ,
2 the ‘son‘ of Serug, the ‘son‘ of Amos, the ‘son‘ of Cosam, the ‘son‘ of Nathan, the ‘son‘ of David,
3 the ‘son‘ of Jesse , the ‘son‘ of Obed, the ‘son‘ of Obed, the ‘son‘ of Salmon, the ‘son‘ of Nahshon,
4 the ‘son‘ of Serug, the ‘son‘ of Reu, the ‘son‘ of Arphaxad, the ‘son‘ of Shem , the ‘son‘ of Noah, the ‘son‘ of Lamech,
5 the ‘son‘ of Melea, the ‘son‘ of Enoch, the ‘son’ of Jared, the ‘son‘ of Mahalaleel, the ‘son‘ of Perez, the ‘son‘ of Eber ,
6 the ‘son‘ of Cainan, the ‘son’ of Jared, the ‘son‘ of Seth, the ‘son‘ of Adam, the ‘son‘ of God .
Here, the genealogy is completely disordered and manipulated. But it is not completely wrong. For example, Father of Abraham is Terah, who is son of Naho. This is the greatest danger. Half truths.
I’ve added more generated samples in the project repo. You may notice more interesting chunks, if you through them.
So, you are telling us that your trained model is the best?

Nope. It is not. The main leak is in chronological order. Though model narrates the incidents well, it does it in random order. So continuity of reading will be missed. How to improve it?
Well… I’m working on it … 🤔
Finally, Why I chose the Gospels as data?
- If the Bible can be generated and manipulated by a mathematical algorithm, then surely it can be exploited by humans. Unlike LSTMs, humans are gifted with a neocortex, which make us million times creative than any mathematical algorithm. Gospel of LSTMs helps convince ourselves the essence of this argument.
- Since the holy scriptures can be manipulated and interpreted like any other literature work, it can be used for promoting a propaganda. Each Bible versions narrates with different words and interpret those words for the preaching. Many of these words could be a poor translation of original version and are misleading at times. You can read more about Bible Errata at here. This project is a pinch to people who blindly follow the verses word by word in the vulnerable holy book.
- For giving a tight slap on the bum of people who use holy books interpretations as an excuse for personal benefits, spread hatred and encourage violence. If a mathematical algorithm can generate a scripture artificially with it’s own interpretations, don’t place that scripture above the humanity.
I’m a Keralite. Last month, our state faced the fiercest flood since 1924. 350+ people died. Audited loss is 25000 crores. Around 10 lakh people were in rescue camps. Now, we are together fighting to restore the normal life of our beautiful state. Before the floods, two incidents happened. One, a catholic bishop was charged for sexually abusing a nun. Two, a motion was filed against the norm that prohibits entry of women to Sabarimala, the well known pilgrimage centre in our state. Women are suppose to pollute the holiness of the place, the orthodox says. During flood, some extremists released a propaganda that, the calamity was result of making gods angry on above mentioned incidents. They quoted these scriptures in favour of it. The project is dedicated for those hatemongers who wanted to segregate humans with religion and gender at the time of a calamity.
Language modelling is applicable to any other holy book not just Bible. I didn’t try Gita or Quran or any other scriptures, since I couldn’t find a convenient data source. That’s it.
Where the hell is the link to project repo repeatedly mentioned in the post?
GitHub repository link: https://github.com/sleebapaul/gospel_of_rnn.git
Can I explicitly get the links to those tutorials you’ve written?
YASSS!!!

Tutorial 1: https://sleebapaul.github.io/rnn-tutorial/
Tutorial 2: https://sleebapaul.github.io/rnn-tutorial-2/
Shameless Plug
I’ve submitted a talk idea to PyCon 2018 on the same project. If you think, this is worth it, then give a thumbs up at the following link. It matters :)
PyCon proposal link: https://in.pycon.org/cfp/2018/proposals/gospel-of-lstm-how-i-wrote-5th-gospel-of-bible-using-lstms~elLMe/
Edit:
AAAGHHH !! They rejected my proposal. So don’t waste your time.

Sleeba Paul
Dreamer | Learner | Storyteller